[Docker] 도커란 무엇인가..
백엔드 개발자라면 배포와 운영까지 염두에 둔 실행 환경을 설계해야 한다. 그리고 그 출발점은, 어쩌면 로컬에서부터 동일한 환경을 재현할 수 있게 해주는 Docker가 아닐까?
![[Docker] 도커란 무엇인가..](/_next/image?url=https%3A%2F%2Fvelog.velcdn.com%2Fimages%2Fgumraze%2Fpost%2F3f3ec6c3-2c9c-4cbb-a871-a27991108f50%2Fimage.png&w=3840&q=75)
서론
풀스택 과정 부트캠프에서 프론트엔드 개발자와 백엔드 개발자가 함께 개발을 수행하다보니 개발 환경의 차이에 의한 문제 그리고 여러 공개할 수 없는 API Key와 같은 것들 때문에 환경을 관리하는 것이 어려웠다.
나는 Docker라는게 있는지는 알고 있었지만 자세히는 알지 못했고, 프로젝트 과정 중에 Docker에 능숙한 팀원이 환경설정을 해준 덕에 환경 설정부터 CI/CD까지 배포와 관련된 문제를 원활히 해결하고 프로젝트를 잘 수행했던 경험이 있다.
당시에는 Docker에 대해 잘 모르고 구성을 했다면, 이제는 Docker에 대해 배경부터 공부해보고 내 프로젝트에 적용한 과정을 설명하려고 한다.
1. Docker의 탄생 배경
도커에 관한 밈을 찾아보게 되었는데 이거로 도커에 대한 많은게 설명되는거 같다.

다음 밈에서 말하고 있는 것은 다음과 같다.
- 내 컴퓨터에서는 작동해! - 그럼 너의 컴퓨터를 배송하자! (울고 있는 개발자)
이런 종류의 밈은 개발 원리나 동작에 대해 참 쉽게 설명해주는 것 같다.
1.1) Docker 이전의 문제
프로젝트가 커지거나 팀원이 늘어나면, 실행 환경의 차이가 쉽게 문제가 된다.
- OS 버전(Windows/macOS/Linux) 차이
- 런타임/패키지 버전 차이 (Java/Node/Python 등)
- 라이브러리 설치 상태 차이
- 환경 변수(
.env), 인증 정보(API Key), 설정 파일 차이 - 로컬/서버의 폴더 구조, 권한, 포트 충돌 등
이런 차이들이 쌓이면 결국, "정확히 어떤 환경에서 어떻게 실행되는지"를 재현하기 어려워지고, 배포 과정에서 예측 불가능한 오류가 쌓인다.
1.2 기존 해법
도커 이전에도 사실은 환경을 통일하려는 시도는 있었다고 한다. 대표적으로 VMware 같은 가상머신(Virtual Machine, VM)이다.
가상머신은 서버 환경(OS 포함)을 통째로 복제하므로,
- 격리성이 좋으며
- 그 서버 그대로 옮기는 방식이라 이식성이 좋다.
하지만 가상머신에는 다음과 같은 현실적인 단점들이 있었다.
- 무겁고 느림: 게스트 OS까지 포함하므로 이미지가 크고 실행/부팅 비용이 크다.
- 밀도가 낮음: 한 서버에 많은 인스턴스를 띄우기 어렵다.
- CI/CD 에 불리: 빠르고 만들고 빠르게 버리는 워크플로에 부담이 크다.
즉, 가상머신 "환경 통일"에는 효과적이지만, 속도와 운영 효율 면에서 현대적인 개발 사이클과 맞지 않은 지점이 있다.
도커에서의 인스턴스: 이미지를 기반으로 실제로 만들어져 실행 중인 하나의 컨테이너로, 이미지는 앱 실행에 필요한 것들을 파일로 묶어놓은 패키지, 컨테이너는 이미지를 기반으로 만들어진 실행 중인 프로세스(실행본)이다.
1.3 Docker의 방식
그러나 도커는 새로운 패러다임을 만든 것은 아니다. 기존에 있었던 **컨테이너라는 방식(OS를 통째로 포함하지 않고, 실행 환경을 더 가볍게 포장하는 방식)**위에 ,
- 애플리케이션을 이미지라는 단위로 패키징하고,
- 어디서든 동일하게 실행할 수 있도록 실행/배포 흐름을 표준화했다는 데 있다.
결과적으로 도커는 다음을 가능하게 했다.
- 내 컴퓨터 실행 환경을 그대로 포장하여 배포 단위로 만듦
- 개발/테스트/운영 환경의 차이를 줄여 재현성 높이기
- CI/CD에서 빠르게 빌드하고 배포하는 흐름 만들기
위를 통해서 도커는 **"환경 차이 때문에 생기는 문제"**해소하고 거의 표준처럼 많이 사용하는 기술이 되었다.
2. VM vs Container
컨테이너에 대해 설명하기 전에 간단하게 가상머신(VM)에 대해 살펴보고자 한다.
2.1 가상머신이란?
가상머신은 말 그대로 가상 컴퓨터 한대이다.
- 물리 서버 위에서
- 하이퍼바이저가
- 가상의 하드웨어를 만들어주고
- 그 위에 게스트 OS를 설치해서 실행한다.
설명이 어렵지만, 간단히 말해서 OS까지 포함해서 서버 한 대를 통째로 복제하는 방식이다.
따라서 가상머신 A와 가상머신 B를 띄우게 되면
- 사실상 서로 다른 컴퓨터처럼 작동하며,
- 커널도 각각 따로 돌아 격리성이 매우 높다.
그러나 다음 문제가 있다.
- OS를 띄우고 부팅해야함 → 시작이 느림
- OS 자체가 포함됨 → 이미지가 커짐
- 자원도 OS 단위로 먹음 → 밀도가 떨어짐
2.2 컨테이너란?
그래서 호스트 OS(실제 물리 서버, 나의 컴퓨터) 위에서 실행되는 격리된 프로세스를 컨테이너라고 한다.
즉, 컨테이너는 OS를 새로 띄우는 방식이 아니라 호스트의 커널을 공유하면서 프로세스를 격리한다. 컨테이너에서 격리는 실제로는 호스트에서 실행되는 프로세스인데,
- 파일시스템이 분리되어 보이고,
- 네트워크가 분리되어 보이고,
- 프로세스 목록이 분리되어 보이고,
- 자원 사용량도 제한할 수 있게
마치 자기만의 작은 OS 환경 처럼 보이게 만드는 것이다. 그런데 가상머신의 목표와 동일하게 핵심을 변하지 않는다.
참고) Docker Desktop을 사용하는 경우, macOS/Windows 커널을 직접 공유하는 것이 아니라, 내부적으로 제공되는 Linux 환경의 커널을 공유하는 형태로 동작한다. 따라서, 커널 공유는 **Linux 커널을 공유한다.**로 이해하는 것이 정확하다.
따라서 호스트 커널을 공유로 커널을 새로 띄우지 않기 때문에 가상머신보다 가볍고 빠르다.
3. 컨테이너가 가능한 이유: 리눅스 커널 3종 세트
앞에서 설명한대로 컨테이너는 파일시스템/네트워크/프로세스를 분리한다고 했는데, 이게 어떻게 가능했는지를 다뤄보고자 한다.
앞에서 컨테이너를 다음과 같이 정의했다.
컨테이너는 호스트 OS 위에서 실행되는 격리된 프로세스이며, 호스트 커널을 공유하지만, "자기만의 작은 OS 환경"처럼 보이게 만든다.
여기서 가장 궁금한 점은 다음과 같다.
- 같은 커널을 공유하는데 어떻게 "분리되어 보이게" 만들까?
- 어떻게 서로의 프로세스를 못 보게 하며, 네트워크도 나눠 쓰고, 자원도 제한할까?
컨테이너의 격리/제한은 주로 리눅스 커널 기능 조합으로 구현된다. 핵심은 다음 2가지다.
- [격리] Namespaces: "보이는 세계"를 분리한다.
- [제한/쿼터] cgroups: 사용할 수 있는 자원을 제한한다.
그리고 Docker의 이미지 레이어(레이어 재사용, Copy-on-Write) 구조는 보통 다음과 같은 스토리지/유니온 파일 시스템으로 구현된다.
- [레이어/CoW] Union/Overlay 계열 파일시스템: 파일 시스템을 레이어로 쌓고 변경분을 효율적으로 관리한다.
3.1 Namespaces
Namespaces는 한마디로 프로세스가 바라보는 시스템 자원 뷰(view)를 분리하는 기능이다.
같은 호스트에서 돌고 있는 프로세스라도, 네임스페이스로 격리하면,
- 내가 보는 프로세스 목록
- 내가 보는 네트워크 인터페이스
- 내가 보는 파일시스템 루트 를 다르게 설정할 수 있다.
여기서 컨테이너가 자기만의 OS처럼 보이는 이유가 나온다.
3.2 cgroups
네임스페이스는 보이는 세상을 분리한다면, cgroups(control groups)는 자원 사용량을 제한한다.
이 컨테이너는 CPU를 몇 %까지, 메모리는 몇 MB까지 사용하게 하자.
따라서 Docker에서 자주 보게 되는 옵션들도 cgroups 기능을 활용한 것이다.
- 메모리 제한
- CPU 제한
- 프로세스 수 제한
- 디스크 I/O 제한 등
3.3 Overlay/Union Filesystem
도커를 사용하다보면 이미지라는 개념이 중요하게 나타난다.
이미지는 앱 실행에 필요한 파일들을 묶어 놓은 패키지인데, 도커 이미지가 효율적인 이유는 보통 레이어 구조 때문이다.
레이어의 개념
예시로 어떤 이미지가 다음을 포함한다고 하자.
- ubuntu base
- apt로 설치한 패키지들
- 애플리케이션 코드
- 실행 설정
이것을 매번 통째로 복사해서 만들면 너무 비효율적이다.
따라서 도커는 파일시스템을 레이어로 쌓아.
- 바뀌지 않는 레이어는 재사용하고
- 바뀐 레이어만 새로 만들도록 한다.
이 레이어 기반 구조를 가능하게 하는 대표적인 기술은 OverlayFS 같은 유니온 파일시스템이다.
컨테이너 실행 시
따라서 컨테이너가 실행 될 때 일반적으로
- 이미지 레이어는 읽기 전용(read-only)
- 컨테이너마다 쓰기 레이어(write layer)가 하나 붙는다.
그래서 컨테이너 내부에서 파일을 수정해도, 실제로는 컨테이너의 쓰기 레이어에 변경분이 쌓이는 구조가 된다.
이 구조 덕분에 다음이 자연스럽게 형성된다.
- 컨테이너는 쉽게 만들고 버릴 수 있다. (휘발성)
- 데이터를 남기려면 볼륨(volume)이 필요하다.
3.4 컨테이너는 커널 기능의 조합이다.
따라서 리눅스 커널 기능(Namespaces, cgroups, overlayFS)를 조합하여 작은 OS 처럼 보이지만 실제로 프로세스인 컨테이너 기능을 만든 것이다.
4. Docker 핵심 개념 6가지

리눅스의 기능을 이용하여 도커는 위 프로세스를 표준화 해주는 기술이다. 이를 이해하기 위해 각각의 개념을 살펴보자
- 이미지(Image)
- 컨테이너(Container)
- 도커파일(Dockerfile)
- 레지스트리(Registry)
- 볼륨(Volume)
- 네트워크(Network)
4.1 이미지
이미지는 컨테이너를 만들기 위한 템플릿으로 다음과 같은 것들을 파일 묶음으로 패키징한 결과물이다
- 애플리케이션 코드
- 런타임/라이브러리
- 설정 파일
- 어떤 명령으로 실행할지(
CMD/ENTRYPOINT)
이미지는 중요한 성질이 있다.
- 불변(immutable)에 가깝게 다룬다. 이미지는 실행하면서 이미지 자체를 바꾸는 게 아니라, 이미지를 다시 빌드해서 새 버전을 만든다.
- 레이어로 구성된다. 바뀌지 않는 부분은 재사용되고, 바뀐 부분만 새로 쌓인다.
다시 말해, **이미지 = 컨테이너의 설계도(템플릿)**이다.
4.2 컨테이너
컨테이너는 이미지를 기반으로 만들어진 실행 중인 프로세스이다.
- 이미지가 정적인 패키지라면,
- 컨테이너는 동적으로 실행되는 실체이다.
컨테이너는 다음 특징이 있다.
- 같은 이미지로 여러 컨테이너를 동시에 띄울 수 있다.
- 컨테이너는 기본적으로 휘발성이다.
- 컨테이너를 지우면 컨테이너 내부 변경사항도 사라진다.
- 그래서 데이터는 볼륨으로 분리한다.
즉, 컨테이너 = 이미지를 실행한 인스턴스(격리된 프로세스)이다.
4.3 도커 파일
도커파일(dockerfile)은 어떤 이미지를 어떤 순서로 만들 것인지를 적어두는 빌드 스크립트이다.
즉, 누가 어떤 컴퓨터에서 빌드를 하든 똑같은 이미지가 나오도록 빌드 과정을 표준화 해주는 역할을 한다.
도커파일에서 자주 나오는 키워드들은 다음과 같다.
FROM: 베이스 이미지 선택WORKDIR: 작업 디렉토리 지정COPY/ADD: 파일 복사RUN: 설치/빌드 명령 실행(레이어 실행)ENV: 환경 변수EXPOSE: 포트 정보로 문서의 성격을 가진다.CMD/ENTRYPOINT: 컨테이너 실행 시 기본 명령
위의 내용을 알아야하는 이유가 있다. 이를 어떤 순서로 작성하느냐에 따라 빌드 캐시 효율이 크게 달라지기 때문이다. 이와 관련해서는 마지막에 다뤄보고자 한다.
4.4 레지스트리
레지스트리는 이미지를 저장/배포하는 저장소로, 이미지 올리고(push) 내려받는(pull) 공간이다.
레지스트리가 중요한 이유는 단순하다.
- 이미지가 있으면 서버에 무엇을 설치했는지(자바 버전, 라이브러리 등)를 일일이 기억할 필요가 없고,
- 서버는 이미지를 내려받아(pull) 실행만 하면 된다.
- CI/CD에서 빌드 산출물이 곧 이미지가 되고, 이 이미지가 배포의 단위가 된다.
예를 들어, 백엔드 앱을 배포한다고 하면 보통 다음 흐름으로 동작한다.
- Dockerfile에서 Java 런타임이 포함된 베이스 이미지 (예:
eclipse-temurin:17-jre)를 선택하고,myapp.jar를 담아 이미지를 만든다. - 만들어진 이미지를 레지스트리에 올린다(push).
- 서버(예: EC2)는 레지스트리에서 이미지를 내려받아(pull) 컨테이너로 실행한다(run).
이 과정 덕분에 서버는 "Java를 어떤 버전으로 설치했는지" 같은 실행 환경을 덜 신경써도 된다.
도커가 설치되어 있고, 이미지를 실행할 수 있으면 된다.
또 다른 예로, Docker Hub는 대표적인 공개 레지스트리이다. 내가 다음을 실행할 때
docker run postgres:16로컬에 postgres:16 이미지가 없다면 도커가 자동으로
- Docker Hub에서
postgres:16이미지를 내려받고(pull) - 내려받은 이미지를 컨테이너로 실행한다(run).
즉, Docker Hub는 postgres 같은 이미지들이 올라가 있는 창고이고, 이런 창고를 레지스트리라고 부른다.
특히 레지스트리가 빛나는 건 CI/CD 시나리오이다.
- GitHub Actions가 이미지를 빌드한다.
- 빌드한 이미지를 레지스트리에 push 한다.
- EC2가 레지스트리에서 pull 한다.
- EC2에서
docker compose up -d또는docker run으로 실행한다.
4.5 볼륨
앞에서 컨테이너는 기본적으로 휘발성이라고 했다. 이 말은 즉, 컨테이너를 지우면 컨테이너 안에서 변경된 파일도 같이 사라질 수 있다는 것을 의미한다.
그런데 일반적으로 백엔드 서비스를 실행시킬 때, DB를 연결하기 때문에 컨테이너 내부에 DB를 같이 띄우게 된다.
그런데 DB는 데이터를 유지하는 것이 생명인데, 컨테이너를 내렸다 올렸다하는 과정에서 데이터가 사라지면 실무에서 사용할 수가 없다.
그래서 도커는 컨테이너와 데이터를 분리하기 위해서 볼륨(Volume)을 제공하고, 볼륨은 컨테이너 밖에서 존재하는 영구 저장소(데이터 저장 공간)이다.
즉, 컨테이너를 삭제하거나 새로 만들어도 볼륨만 그대로 두면 데이터가 유지된다.
그럼 DB 컨테이너가 꺼져도 어떻게 데이터가 저장되는지 살펴보자.
4.5.1 볼륨의 형태
도커에서 볼륨은 두 가지 형태로 사용된다.
(1) Named Volume(도커가 관리)
- 도커가 관리하는 저장공간에 "이름"을 붙여서 사용하는 방식
- 운영/배포 환경에서 흔히 사용함.
- 컨테이너 경로에 깔끔하게 연결 가능함
예: postgres_data 같은 이름을 붙이는 방식
(2) Bind Mount(호스트 경로를 직접 연결)
- 호스트 OS의 특정 폴더를 컨테이너에 그대로 마운트한다.
- 로컬 개발할 때 소스코드 핫리로드 등에서 자주 사용한다.
- 예: 로컬의
./data폴더를 컨테이너/var/lib/postgresql/data에 연결한다.
4.5.2 왜 데이터가 사라지지 않는지?
(1) 컨테이너 내부 파일은 원래 휘발성(사라질 수 있음) 컨테이너는 실행 될 때 설명했듯이 다음과 같이 구성된다.
- 이미지 레이어(읽기 전용) + 컨테이너 쓰기 레이어(읽기/쓰기)
DB가 컨테이너 안에서 데이터를 저장하면, 기본적으로 그 데이터 파일은 컨테이너 쓰기 레이어에 쌓인다. 그래서 해당 컨테이너를 삭제하면 해당 쓰기 레이어가 같이 날아가고, 데이터도 같이 사라진다.
(2) 볼륨을 붙이면 저장 위치가 컨테이너 밖으로 바뀜 Postgres를 예로 들면, DB 데이터는 보통 컨테이너 안의 다음 경로에 저장된다.
/var/lib/postgresql/data
여기에 볼륨을 마운트하면 다음과 같은 일이 발생한다.
- 컨테이너가 이 경로에 쓰는 파일이
컨테이너 내부가 아니라, 볼륨(호스트에 있는 저장공간)에 기록된다.
따라서 컨테이너를
stop해도 프로세스(DB)가 멈출 뿐이지 볼륨에 저장된 파일은 그대로 남아있게 된다.(그냥 디스크 파일이니까)
5. Dockerfile: 환경을 코드로 만드는 방법
위 설명한 내용들을 이제 Dockerfile 설정으로 실습할 수 있다.
Dockerfile은 어떤 이미지를 어떤 순서로 만들 것인지를 적어두는 파일이다. 즉, 개발 환경(설치/빌드/실행 과정)을 코드로 선언해서, 누가 어디서 빌드하든 동일한 이미지를 만든다.
5.1 Dockerfile 기본 구조
Dockerfile은 보통 아래 흐름으로 작성된다
FROM: 어떤 이미지에서 시작할지COPY: 필요한 파일을 복사하고RUN: 필요한 설치/빌드를 수행하고CMD/ENTRYPOINT: 실행 명령을 정의한다.
다음은 Gradle + Java 21을 기준으로 작성된 2개의 Dockerfile에 대해 살펴보고자 한다.
5.1.1 멀티스테이지 빌드
- 빌드 단계에서는 Gradle + JDK 21로
bootJar를 만들고 - 실행 단계에서는 JRE 21만 남겨 이미지를 가볍게 만든다.
# 빌드 단계: Gradle + JDK 21
FROM gradle:8.7-jdk21 AS builder # 이 단계를 builder로 정의
WORKDIR /workspace # 컨테이너 내부에서 작업할 디렉토리를 /workspace로 정의
# 소스 복사 후 빌드
COPY . . # 현재 폴더(프로젝트 전체)를 컨테이너의 작업 디렉토리(/workspace)로 복사
RUN gradle bootJar --no-daemon # 컨테이너 안에서 Gradle 명령으로 Spring Boot 실행 JAR(bootJar)를 생성.
# --no-daemon은 CI/컨테이너 환경에서 Gradle 데몬을 사용하지 않도록 하여 안정적으로 동작하도록 하는 옵션
# 실행: JRE 21, 빌드는 위에서 끝났으며 여기서는 이제 실행만 함.
FROM eclipse-temurin:21-jre # 실행 단계에서 사용할 베이스 이미지
WORKDIR /app # 실행 단계 컨테이너에서 작업 디렉토리를 /app으로 설정함.
# 빌드 산출물(JAR)를 런타임 이미지로 복사
# builder단계에서 만들어진 jar를 가져와서,
# 현재 단계(/app)에 app.jar라는 이름으로 복사한다.
# *.jar는 빌드 결과 jar 이름이 프로젝트마다 달라서 와일드카드로 잡음.
COPY --from=builder /workspace/build/libs/*.jar app.jar
# 이 컨테이너가 8080포트를 사용할 것이라는 메타 정보
# 실제 외부에 포트를 열려면 포트 매핑이 필요함.
EXPOSE 8080
# 컨테이너가 시작될 때 실행할 기본 실행 명령이다.
ENTRYPOINT ["java", "-jar", "app.jar"]위 방법의 장점
- 서버/CI는 소스만 있으면 이미지를 만들 수 있음.
- 실행 이미지는 빌드 도구(Gradle)가 없어서 작고 안전해짐
- 빌드/실행 환경이 분리되어 구조가 깔끔함.
실행 방법 멀티스테이지는 Dockerfile 안에서 빌드까지 진행하므로, 별도 Gradle 빌드 없이 아래만 하면 된다.
# (프로젝트 루트에서) 이미지 빌드
docker build -t myapp:1.0 .
# 컨테이너 실행 (호스트 8080 -> 컨테이너 8080)
docker run -d --name myapp -p 8080:8080 myapp:1.0
# 로그 확인 방법
docker logs -f myapp5.1.2 단순 버전
- 로컬이나 CI에서 먼저
bootJar를 만든 다음, Docker는 실행만 담당하는 구조
FROM eclipse-temurin:21-jre
WORKDIR /app
COPY build/libs/*.jar app.jar
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "app.jar"]실행 방법 단순 버전은 이미 build/libs에 jar가 있어야하므로 먼저 빌드를 한다.
# 먼저 jar 생성
./gradlew bootJar
# 이미지 빌드
docker build -t myapp:1.0 .
# 컨테이너 실행
docker run -d --name myapp -p 8080:8080 myapp:1.02가지 dockerfile을 구성하는 방법을 살펴보았는데,
실제 백엔드 개발에서는 단일 API 서버만 띄우는 경우가 드물고,
보통 DB, 캐시 등 여러 컨테이너가 함께 필요하다.
다음으로는 이 구성을 docker compose up 한 줄로 통일하는 방법을 정리해보자.
6. Docker Compose: 개발 환경을 1줄로 맞추는 방법
앞에서는 Dockerfile로 Spring Boot 애플리케이션 이미지를 만들고 docker run으로 실행하는 방법을 살펴봤다.
하지만 실제 백엔드 개발에서는 API 서버만 단독으로 띄우는 경우가 드물고, 보통은 다음과 같은 구성 요소가 함께 필요하다.
- API 서버(Spring Boot)
- DB(Postgres)
- 캐시(Redis)
- 프록시(Nginx)
이런 구성을 매번 docker run ... 명령으로 하나씩 띄우려면 포트, 환경 변수, 네트워크. 볼륨 설정이 길고 복잡해진다.
그래서 이를 Docker Compose가 해결해준다.
docker-compose.yml: 여러 컨테이너(서비스)의 실행 구성을 한 파일로 정의함.docker compose up한 줄로 동일한 개발 환경을 띄울 수 있게 해줌.
6.1 docker-compose.yml
Compose는 다음을 한 번에 해결한다. (1) Service: 어떤 컨테이너들을 띄울지 (2) Image/build: 각 컨테이너는 어떤 이미지로 실행할지 (3) Ports: 포트를 어떻게 열지 (4) environment/env_file: 환경 변수/시크릿을 어떻게 주입할지 (5) volumes: 데이터를 어디에 저장할지 (6) network: 컨테이너끼리 어떻게 통신할지
6.2 예제: Spring Boot + Postgres 구성
Spring Boot API 서버와 Postgres DB의 개발 환경을 구성하는 예시를 보고자 한다.
api: Spring Boot 애플리케이션(Dockerfile로 빌드)db: Postgres DB (공식 이미지 사용)postgres_data: DB 영구 저장을 위한 볼륨
services:
db:
image: postgres:16
container_name: myapp-db
environment:
POSTGRES_DB: myapp
POSTGRES_USER: myapp
POSTGRES_PASSWORD: myapp_pw
ports:
- "5432:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
api:
build: .
container_name: myapp-api
depends_on:
- db
ports:
- "8080:8080"
environment:
# DB 컨테이너의 서비스 이름(db)로 접근
SPRING_DATASOURCE_URL: jdbc:postgresql://db:5432/myapp
SPRING_DATASOURCE_USERNAME: myapp
SPRING_DATASOURCE_PASSWORD: myapp_pw
volumes:
postgres_data:DB 주소가 localhost가 아니라 db인가? Compose에서는 같은
docker-compose.yml에 정의된 서비스들이 기본적으로 같은 Docker 네트워크에 묶인다. 그리고 그 네트워크 안에서는 서비스 이름(여기서는db)이 호스트명(DNS) 처럼 동작한다.그래서 API 컨테이너에서 DB에 접속할 때 다음과 같이 된다.
localhost:5432→ 여기서는 localhost는 API 컨테이너 자기 자신이 됨.db:5432→ 같은 네트워크의 DB 컨테이너
6.3 실행 방법
Compose의 장점은 실행이 단순하고 쉬워진다는 것이다.
# 컨테이너들을 백그라운드로 실행
docker compose up -d
# 실행 중인 컨테이너 확인
docker compose ps
# 로그 확인(전체)
docker compose logs -f
# 특정 서비스 로그만 확인(예:api)
docker compose logs -f api종료는 다음처럼 한다.
# 컨테이너 종료 및 네트워크 정리(볼륨은 유지됨)
docker compose down
# 볼륨까지 같이 삭제(= DB 데이터도 삭제됨)
docker compose down -v7. Docker의 한계
Docker는 이미지로 실행 환경을 표준화하고, 컨테이너로 빠르게 실행하는 방식을 통해 배포와 개발 환경 통일을 쉽게 만들었다.
그런데 최근 실세 서비스 운영 환경에서는 Kubernetes를 함께 사용하는데, 그 이유를 Docker의 한계와 함께 살펴보고자 한다.
나도 아직 사용해보지는 않았다.
7.1 운영 단위로의 컨테이너
Docker를 처음 사용할 때 보통 다음과 같이 사용한다.
docker run으로 컨테이너 실행docker compose up으로 여러 서비스 실행
이것은 로컬 개발 환경이나 작은 규모에서는 충분히 잘 동작한다. 하지만 서비스가 성장하면, 컨테이너는 단순한 실행 단위가 아니라 운영 단위가 된다. 이 때부터 Docker로만으로 서비스를 제공하는데 한계가 있다고 한다.
7.2 한계점
7.2.1 휘발성
컨테이너는 기본적으로 쉽게 만들고 쉽게 버릴 수 있도록 설계된 실행 단계로 휘발성이다. 컨테이너 내부 파일 시스템에 의존하면, 컨테이너 삭제/교체 시 **상태(state)**가 사라질 수 있다.
따라서, 다음 조치를 취한다.
- DB 데이터 → 볼륨/외부 DB로 분리 필요
- 로그/업로드 파일 → 외부 저장소(S3, 로그 시스템 등)로 분리 필요
- 세션/캐시 → Redis 같은 외부 저장소로 분리 필요
즉, Docker 자체가 문제라기보다 컨테이너 운영을 시작하면 상태를 분리하는 설계가 필수가 된다. 또한, Docker 공식 문서에서도 컨테이너는 Ephemeral(쉽게 중지/파괴/재생성 가능)하게 만들어야한다고 한다.
7.2.2 많은 컨테이너의 운영 및 관리
서비스가 적은 경우에는 docker run, docker compose로도 충분하지만,
하지만 서비스가 많아지거나(MSA), 트래픽 변화에 따라 인스턴스를 늘려야 하는 순간부터 수동 운영은 한계가 온다.
예시로 운영에서 실제로 필요한 작업은 다음과 같다고 한다.
- 컨테이너가 죽으면 자동으로 재시작
- 새 버전 배포 시 무중단 배포
- 문제가 생기면 빠르게 롤백
- 트래픽 증가 시 자동으로 스케일 아웃/인
- 여러 서버에 컨테이너를 적절히 분산 배치
이것을 Docker만으로는 가능은 하지만, 규모가 커질 수록 어려우며 비용이 급격하게 늘어난다고 한다.
7.2.3 네트워크/서비스 찾기가 더 어려워진다.
컨테이너는 생성/삭제가 빠르고, 운영/개발 과정에서 구성이 자주 바뀐다.
즉, 컨테이너의 IP는 고정되지 않는 경우가 많고, **호스트(내 PC/서버)에서 바라보는 접속 정보도 설정에 따라 달라질 수 있다.
이것은 실제 부트캠프 프로젝트에서도 겪었던 문제다. 프로젝트 기간이 짧다 보니 서버를 자주 재시작하거나 DB를 초기화하는 작업이 반복됐는데, 그 과정에서 DB 접속 포트가 매번 달라져 연결 문제가 생겼던 경험이 있다.
엄밀히 말하면 DB 초기화가 포트를 바꾸는 것은 아니며, 보통 포트가 달라지는 원인은 다음 중 하나이다.
ports에서 호스트 포트를 고정하지 않은 경우- 포트 충돌
따라서 운영/협업 환경에서는 보통 다음을 신경써야한다.
- 어떤 서비스가 어디에 떠 있는지(서비스 디스커버리)
- 어떻게 안정적으로 연결할지(고정된 엔드포인트/서비스 이름)
- 어떻게 트래픽을 분산할지(로드 밸런싱)
- 장애 인스턴스를 트래픽에서 어떻게 제외할지(헬스체크/자동 복구)
7.3 Kubernetes의 필요성
정리하면 Docker는 컨테이너라는 실행 방식을 표준화 했지만, 서비스가 커질수록 다음 요구가 생긴다.
- 자동 배치/스케줄링
- 자동 복구
- 배포 전략
- 스케일링
- 서비스 디스커버리/로드밸런싱
- 구성/비밀키 관리
위 요구를 운영 가능한 수준으로 해결하는 프레임워크가 오케스트레이션이고, 대표적으로 Kubernetes이다.
즉, Docker는 컨테이너를 만들고 실행하는 표준이라면, Kubernetes는 컨테이너가 많은 시스템을 운영하게 만드는 표준이다.
마치며,,,
부트캠프 프로젝트에서 매 프로젝트 때마다 도커를 사용했었다. 그 이유는 개발 환경의 차이를 줄이기 위함, 배포를 위함 등이었는데, 실제 도커가 어떤 배경과 원리를 가지고 동작하는지 자세히 알지 못했다.
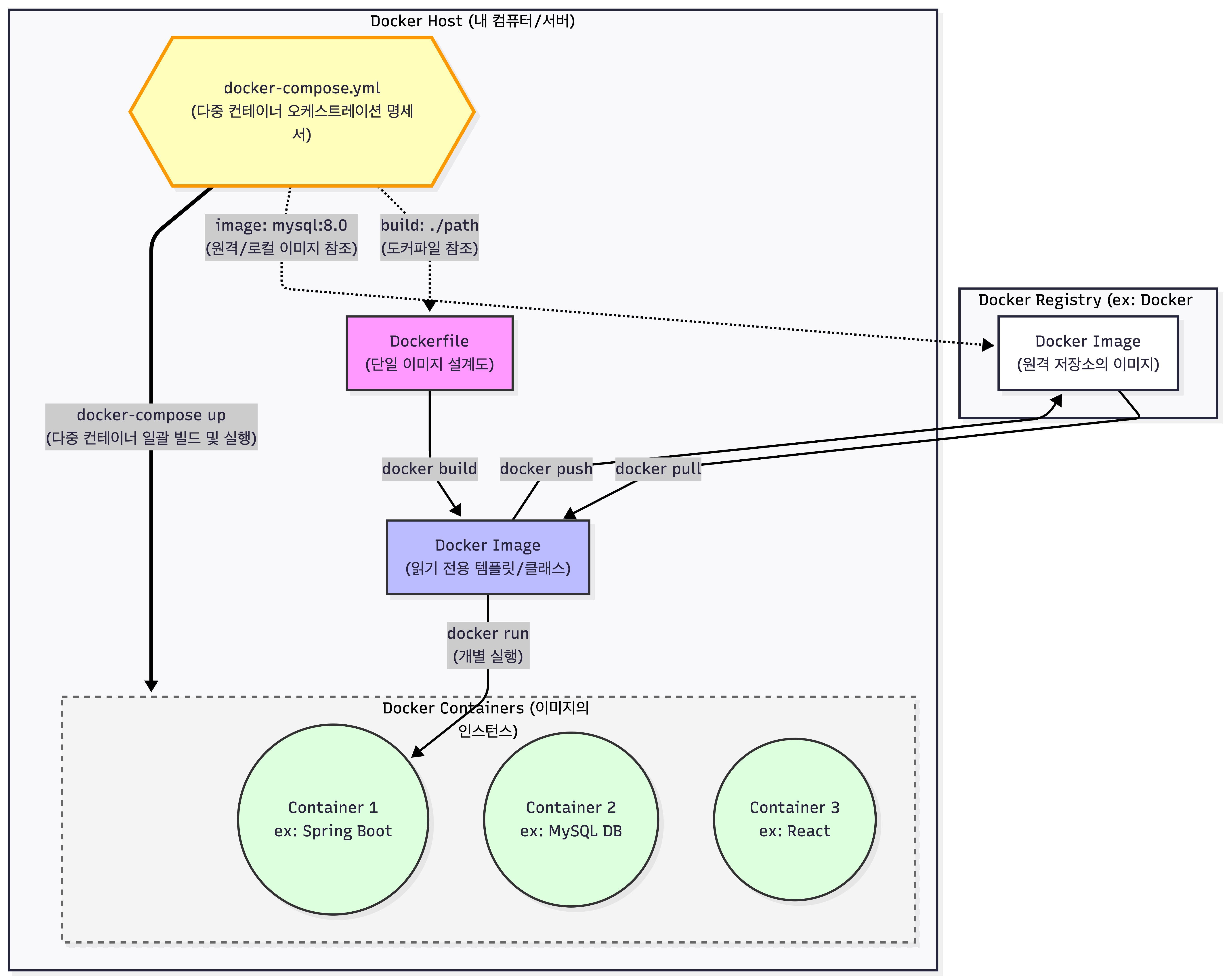
따라서 이번에 위와 같은 구조로 간단히 공부한 것을 정리해보았고, 항상 취업 공고에 도커와 함께 쿠버네이스가 등장하는데, 이것의 필요성까지 한 번 찾아보았다.
다음으로는 쿠버네티스에 대해 간단히 다뤄보고자 한다.